routing和replica的读写过程
之前两节,完整介绍了在单个 Lucene 索引,即 ES 分片内的数据写入流程。现在彻底回到 ES 的分布式层面上来,当一个 ES 节点收到一条数据的写入请求时,它是如何确认这个数据应该存储在哪个节点的哪个分片上的?
路由计算
作为一个没有额外依赖的简单的分布式方案,ES 在这个问题上同样选择了一个非常简洁的处理方式,对任一条数据计算其对应分片的方式如下:
shard = hash(routing) % number_of_primary_shards
每个数据都有一个 routing 参数,默认情况下,就使用其 _id 值。将其 _id 值计算哈希后,对索引的主分片数取余,就是数据实际应该存储到的分片 ID。
由于取余这个计算,完全依赖于分母,所以导致 ES 索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,所以数据的存储位置计算结果都会发生改变,索引数据就完全不可读了。
副本一致性
作为分布式系统,数据副本可算是一个标配。ES 数据写入流程,自然也涉及到副本。在有副本配置的情况下,数据从发向 ES 节点,到接到 ES 节点响应返回,流向如下(附图 2-9):
- 客户端请求发送给 Node 1 节点,注意图中 Node 1 是 Master 节点,实际完全可以不是。
- Node 1 用数据的
_id取余计算得到应该讲数据存储到 shard 0 上。通过 cluster state 信息发现 shard 0 的主分片已经分配到了 Node 3 上。Node 1 转发请求数据给 Node 3。 - Node 3 完成请求数据的索引过程,存入主分片 0。然后并行转发数据给分配有 shard 0 的副本分片的 Node 1 和 Node 2。当收到任一节点汇报副本分片数据写入成功,Node 3 即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1 返回成功响应给客户端。
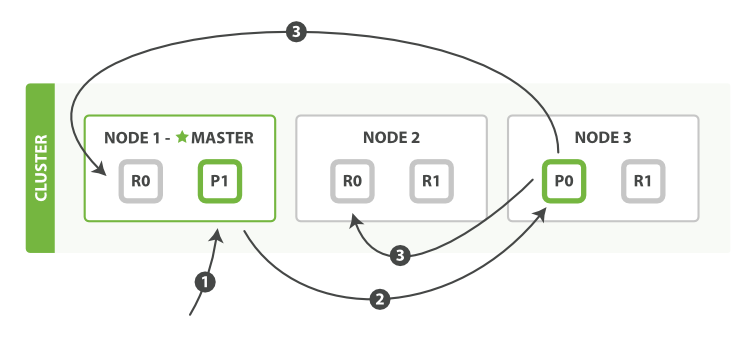 图 2-9
图 2-9
这个过程中,有几个参数可以用来控制或变更其行为:
- wait_for_active_shards 上面示例中,2 个副本分片只要有 1 个成功,就可以返回给客户端了。这点也是有配置项的。其默认值的计算来源如下:
int( (primary + number_of_replicas) / 2 ) + 1
根据需要,也可以将参数设置为 one,表示仅写完主分片就返回,等同于 async;还可以设置为 all,表示等所有副本分片都写完才能返回。
- timeout
如果集群出现异常,有些分片当前不可用,ES 默认会等待 1 分钟看分片能否恢复。可以使用
?timeout=30s参数来缩短这个等待时间。
副本配置和分片配置不一样,是可以随时调整的。有些较大的索引,甚至可以在做 forcemerge 前,先把副本全部取消掉,等 optimize 完后,再重新开启副本,节约单个 segment 的重复归并消耗。
# curl -XPUT http://127.0.0.1:9200/logstash-mweibo-2015.05.02/_settings -d '{
"index": { "number_of_replicas" : 0 }
}'