segment merge对写入性能的影响
通过上节内容,我们知道了数据怎么进入 ES 并且如何才能让数据更快的被检索使用。其中用一句话概括了 Lucene 的设计思路就是"开新文件"。从另一个方面看,开新文件也会给服务器带来负载压力。因为默认每 1 秒,都会有一个新文件产生,每个文件都需要有文件句柄,内存,CPU 使用等各种资源。一天有 86400 秒,设想一下,每次请求要扫描一遍 86400 个文件,这个响应性能绝对好不了!
为了解决这个问题,ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。归并过程中,索引状态如图 2-7,尚未完成的较大的 segment 是被排除在检索可见范围之外的:
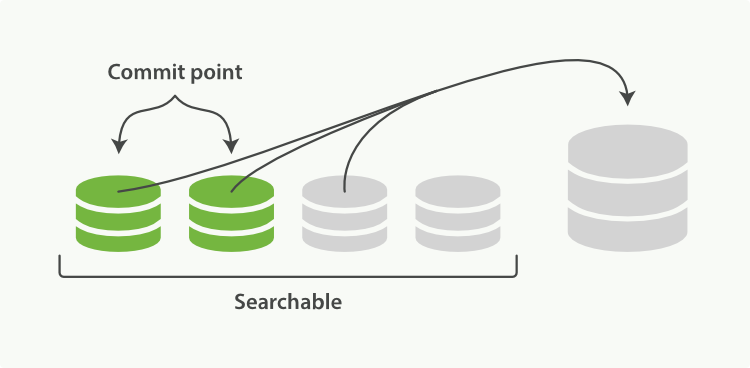 图 2-7
图 2-7
当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了,状态如图 2-8 所示:
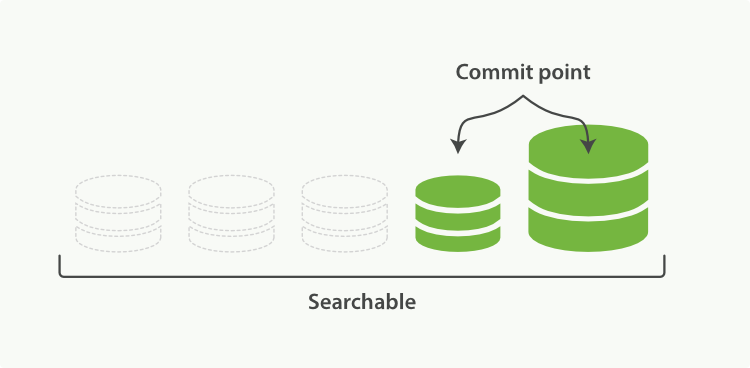 图 2-8
图 2-8
归并线程配置
segment 归并的过程,需要先读取 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,这是一个非常消耗磁盘 IO 和 CPU 的任务。所以,ES 提供了对归并线程的限速机制,确保这个任务不会过分影响到其他任务。
在 5.0 之前,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 Elastic Stack 应用,社区广泛的建议是可以适当调大到 100MB或者更高。
# curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}'
5.0 开始,ES 对此作了大幅度改进,使用了 Lucene 的 CMS(ConcurrentMergeScheduler) 的 auto throttle 机制,正常情况下已经不再需要手动配置 indices.store.throttle.max_bytes_per_sec 了。官方文档中都已经删除了相关介绍,不过从源码中还是可以看到,这个值目前的默认设置是 10240 MB。
归并线程的数目,ES 也是有所控制的。默认数目的计算公式是: Math.min(3, Runtime.getRuntime().availableProcessors() / 2)。即服务器 CPU 核数的一半大于 3 时,启动 3 个归并线程;否则启动跟 CPU 核数的一半相等的线程数。相信一般做 Elastic Stack 的服务器 CPU 合数都会在 6 个以上。所以一般来说就是 3 个归并线程。如果你确定自己磁盘性能跟不上,可以降低 index.merge.scheduler.max_thread_count 配置,免得 IO 情况更加恶化。
归并策略
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
- index.merge.policy.floor_segment 默认 2MB,小于这个大小的 segment,优先被归并。
- index.merge.policy.max_merge_at_once 默认一次最多归并 10 个 segment
- index.merge.policy.max_merge_at_once_explicit 默认 forcemerge 时一次最多归并 30 个 segment。
- index.merge.policy.max_merged_segment 默认 5 GB,大于这个大小的 segment,不用参与归并。forcemerge 除外。
根据这段策略,其实我们也可以从另一个角度考虑如何减少 segment 归并的消耗以及提高响应的办法:加大 flush 间隔,尽量让每次新生成的 segment 本身大小就比较大。
forcemerge 接口
既然默认的最大 segment 大小是 5GB。那么一个比较庞大的数据索引,就必然会有为数不少的 segment 永远存在,这对文件句柄,内存等资源都是极大的浪费。但是由于归并任务太消耗资源,所以一般不太选择加大 index.merge.policy.max_merged_segment 配置,而是在负载较低的时间段,通过 forcemerge 接口,强制归并 segment。
# curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_forcemerge?max_num_segments=1
由于 forcemerge 线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议对还在写入数据的热索引执行这个操作。这个问题对于 Elastic Stack 来说非常好办,一般索引都是按天分割的。更合适的任务定义方式,请阅读本书稍后的 curator 章节。